[DevOps] Kubernetes HPA 실전 적용
안녕하세요? 정리하는 개발자 워니즈입니다. 이번 포스팅은 kubernetes hpa 에 대해서 적용했던 사례에 대해서 정리를 해보려고합니다.
이 전에 작성된 포스팅이긴 하지만, HPA의 이론에 대해서는 아래의 포스팅을 참고해주시면 됩니다.
위의 내용중에서도 HPA(Horizontal Pod Autoscaler)를 실제 적용하는 계획과 실행에 대해서 정리를 해보려고합니다.
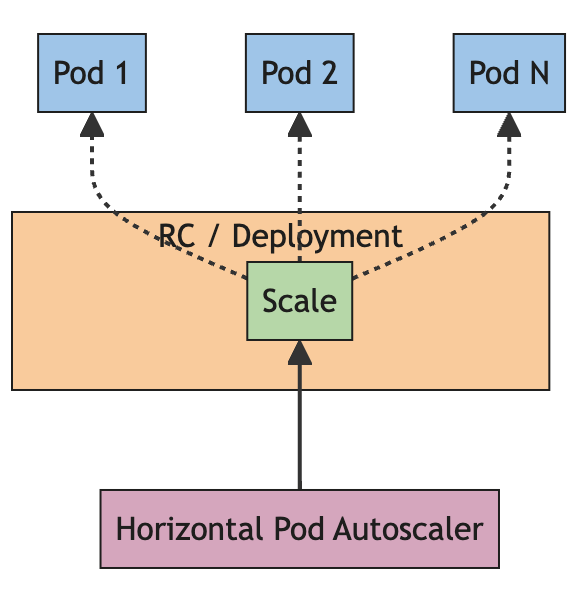
1. HPA 적용 목적 및 정책
필자가 운영하는 k8s에는 100여개 이상의 MSA 어플리케이션들이 서비스를 하고 있습니다. 모든 서비스들이 최적으로 운영된다면 좋겠지만 보통은 보수적으로 pod를 산정하고 리소스를 산정합니다. 자연스럽게 k8s의 리소스가 부족한 현상이 발생하기 시작했고 조치가 필요했습니다.
HPA의 적용 목적은 다음과 같은 내용을 기반으로 하고 있습니다.
- 성능 유지 : 트래픽이나 요청량이 증가할 떄 추가 POD를 자동으로 생성하여 처리 능력을 높입니다.
- 리소스 최적화 : 과도한 리소스 할당을 방지하고, 리소스 사용 효율성을 높입니다.
- 자동화 및 운영 효율성 증대 : 부하 발생시 수동으로 조절하던 부분을 메트릭 측정값을 기반으로 자동 조정합니다.
위의 목적에 기재 되어있듯이 리소스 최적화에도 기반을 두고 작업을 예정하게 되었습니다.
- HPA 적용 정책
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscalermetadata: name: hpa-test namespace: dosi-store spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: {{ .Values.phase }}-test-api minReplicas: 6 maxReplicas: 18 <- 기존대비 3배수로 설정 behavior: scaleDown: stabilizationWindowSeconds: 300 policies: - type: Pods value: 2 periodSeconds: 10 scaleUp: stabilizationWindowSeconds: 30 policies: - type: Percent value: 50 periodSeconds: 10 - type: Pods value: 4 periodSeconds: 10 selectPolicy: Max metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70- minReplicas : 현재의 pod 갯수
- maxReplicas : 최대 증설의 pod 갯수 ( 6 * 3 = 18개로 기준을 잡음 )
- scaleDown
- 10초당 2개의 pod를 감소
- 정책 적용 결정이 수행되면 5분간의 유예기간으로 메트릭을 지속 탐지함.
- 스케일 다운이 바로 일어나면 서비스에 문제가 발생할 수 있을것이라 판단하여 5분간 유예설정.
- scaleUp
- 10초당 현재 갯수의 50% (ex, 현재가 6개면, 3개로 계산 ) / 15초당 4개의 pod를 증가 중 더 큰 범주 선택
- 정책 적용 결정이 수행되면 30초간의 유예기간으로 메트릭을 지속 탐지함.
- 스케일 다운이 바로 일어나면 서비스에 문제가 발생할 수 있을것이라 판단하여 30초간 유예설정.
- 평균 CPU 사용률 70%를 임계점으로 설정.
2. HPA 적용 계획
HPA를 적용함에 있어서 기존의 수집된 Metric을 한달 기준으로 분석을 실시했습니다. 적용 대상이 되는 어플리케이션 선정은 다음을 기준으로 선정했습니다.
- HPA 적용 기준
- 트래픽이 제일 많은 어플리케이션
- 트래픽 대비 과도하게 스케일 아웃되어있는 어플리케이션
- 현재 CPU Usage가 스케일 대비 과도하게 낮은 어플리케이션
트래픽이 많으면서(변동량이 크면서), 서버 수량은 많고 리소스는 최소로 사용하는(오버 스펙)이 되어있는 어플리케이션들의 정보를 수집했습니다.
| 어플리케이션 | 평균 RPS / 최고 RPS | Current Replicas | Cpu Trend | Target Replicas | 비고 |
|---|---|---|---|---|---|
| A application | 22.4 / 69.5 (peak시 cpu 25%) | 12 | Grafana 기록 | 6 | |
| B application | 8.9 / 47.8(peak시 cpu 10%) | 8 | Grafana 기록 | 4 | |
| C application | 16.7 / 53.5(peak시 cpu 10%) | 12 | Grafana 기록 | 6 | |
| D application | 32.1 / 230.2(peak시 cpu 40%) | 12 | Grafana 기록 | 6 | |
| E application | 30.9 / 129.4 (peak시 cpu 16% ) | 12 | Grafana 기록 | 6 |
위의 표와 같이 기록을 수행하여 기존의 CPU 트렌드 기반으로 목표 지점은 CPU Usage를 20 ~ 30% 를 사용하는것을 목표료 하여 Target Replicas를 지정하고 축소 계획을 세웠습니다.
계획은 다음 순서로 진행을 하고자 했습니다.
- 1) HPA 설정 배포 ( 설정은 현재의 서비스에 영향을 미치지 않음. )
- 2) pod수를 스케일 다운. ( 다운시 CPU Usage 기록 )
- CPU Usage의 안정 범위 : 평시에 20-30% 정도 사용.
- 3) 적용이후에는 위의 정책을 기준으로 필요한 어플리케이션에 확장.
3. HPA 적용 테스트
사전에 HPA를 적용하기 이전에 테스트를 진행했습니다. API 1개에 부하를 쏟아서 CPU 임계점을 넘어가도록 설정했습니다.
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
alpha-test-app Deployment/alpha-test-app 3%/70% 2 6 2 11m
alpha-test-app Deployment/alpha-test-app 3%/70% 2 6 2 11m ← 부하 테스트 시작
alpha-test-app Deployment/alpha-test-app 111%/70% 2 6 2 12m ← 임계치 상향
alpha-test-app Deployment/alpha-test-app 111%/70% 2 6 4 12m ← Upscale (30초 유예)
alpha-test-app Deployment/alpha-test-app 45%/70% 2 6 4 13m ← 임계치 하향
alpha-test-app Deployment/alpha-test-app 2%/70% 2 6 4 14m
alpha-test-app Deployment/alpha-test-app 2%/70% 2 6 4 15m
alpha-test-app Deployment/alpha-test-app 2%/70% 2 6 4 16m
alpha-test-app Deployment/alpha-test-app 3%/70% 2 6 4 17m
alpha-test-app Deployment/alpha-test-app 3%/70% 2 6 4 18m ← DownScale (300초 유예)
alpha-test-app Deployment/alpha-test-app 4%/70% 2 6 2 18m
alpha-test-app Deployment/alpha-test-app 4%/70% 2 6 2 19m
alpha-test-app Deployment/alpha-test-app 3%/70% 2 6 2 20m
- Upscale 적용 후
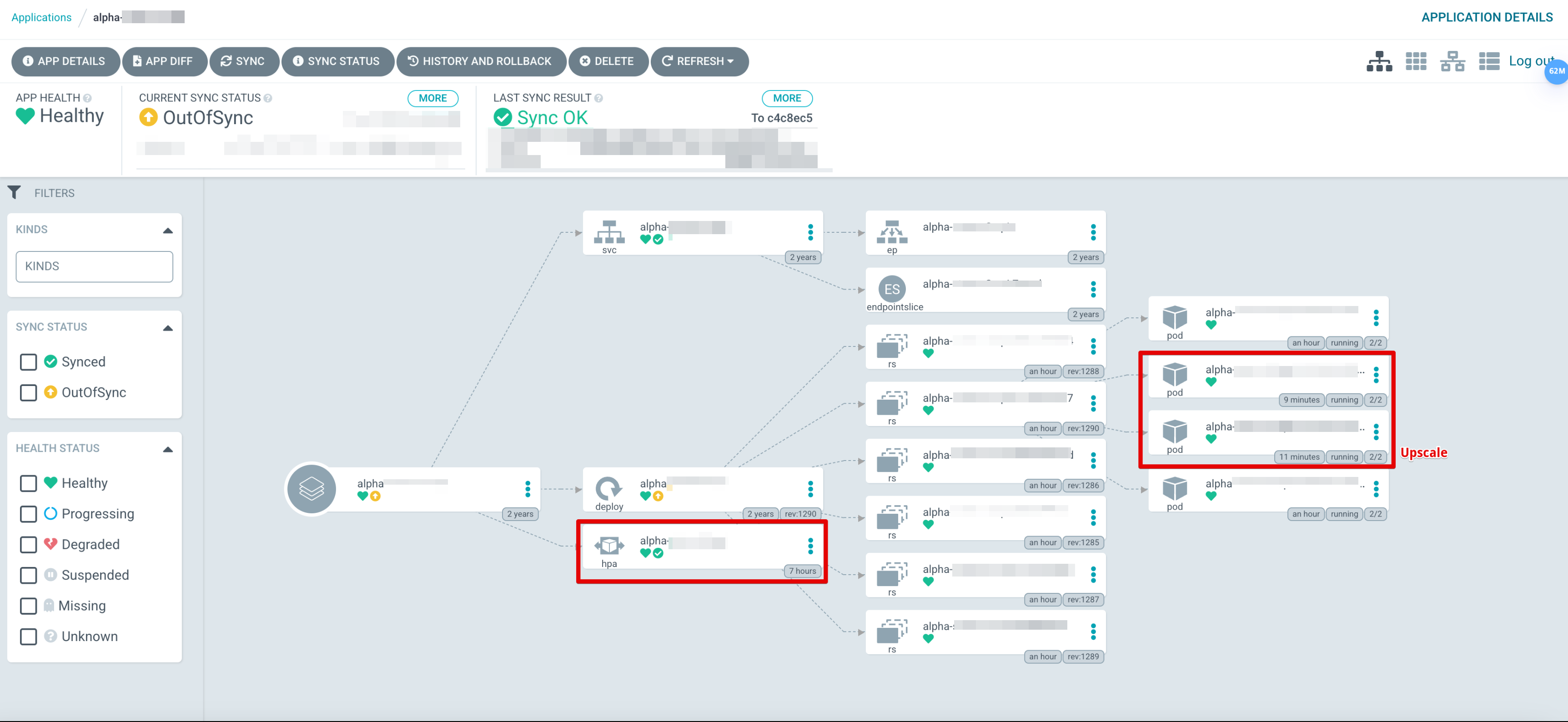
-
Downscale 적용 후
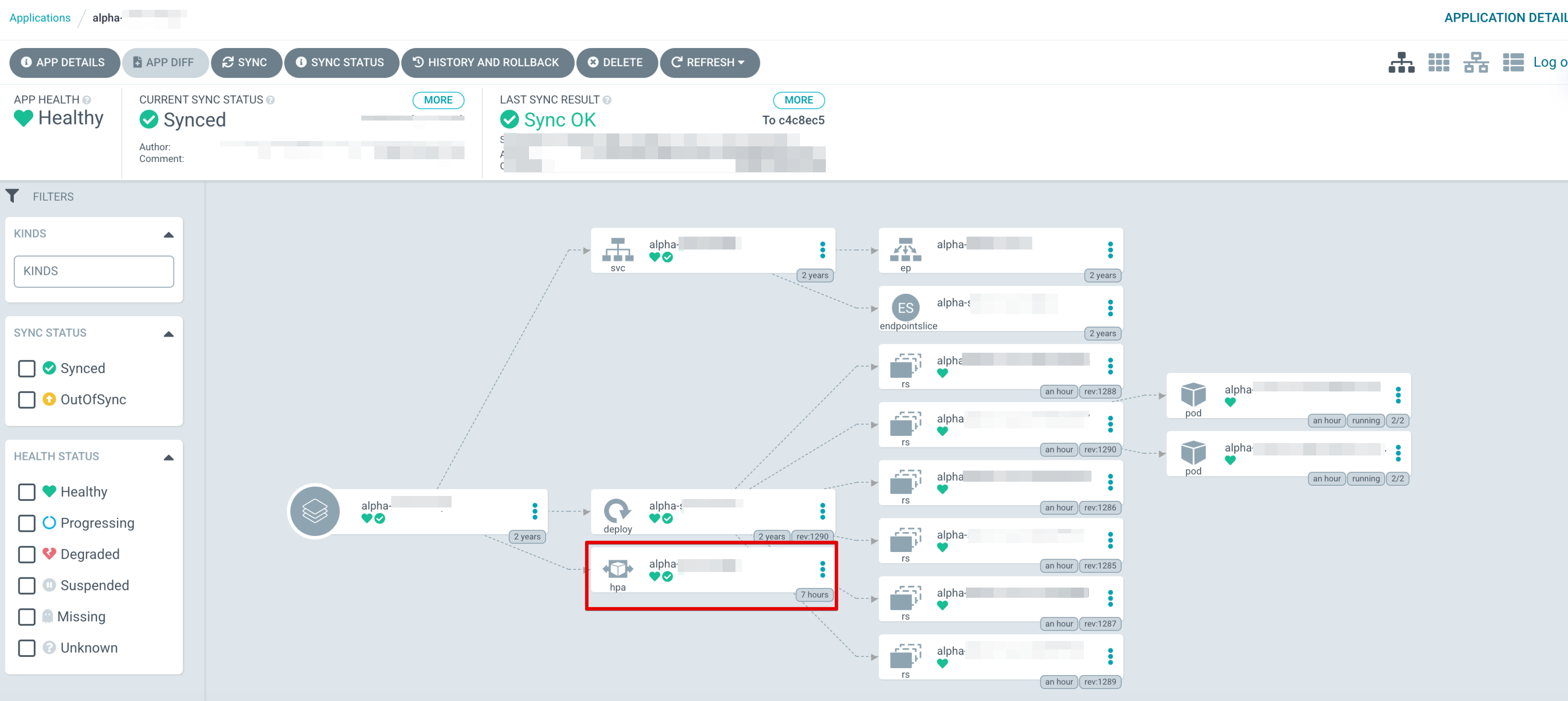
정확하게 HPA 동작에 의해 Upscale을 수행했다가 부하가 사라지면 정상화 됩니다.
- 이슈 사항
테스트를 진행하면서 이슈를 한가지 확인했는데요. 배포를 하게 되면 새로운 어플리케이션으로부터 Metric이 즉각 수집이 되지 않으면서 Degraded상태가 되는것을 확인했습니다. 따라서 Metric이 수집되지 않은 상태라면 Progressing상태로 마킹하는 내용이 필요했습니다.
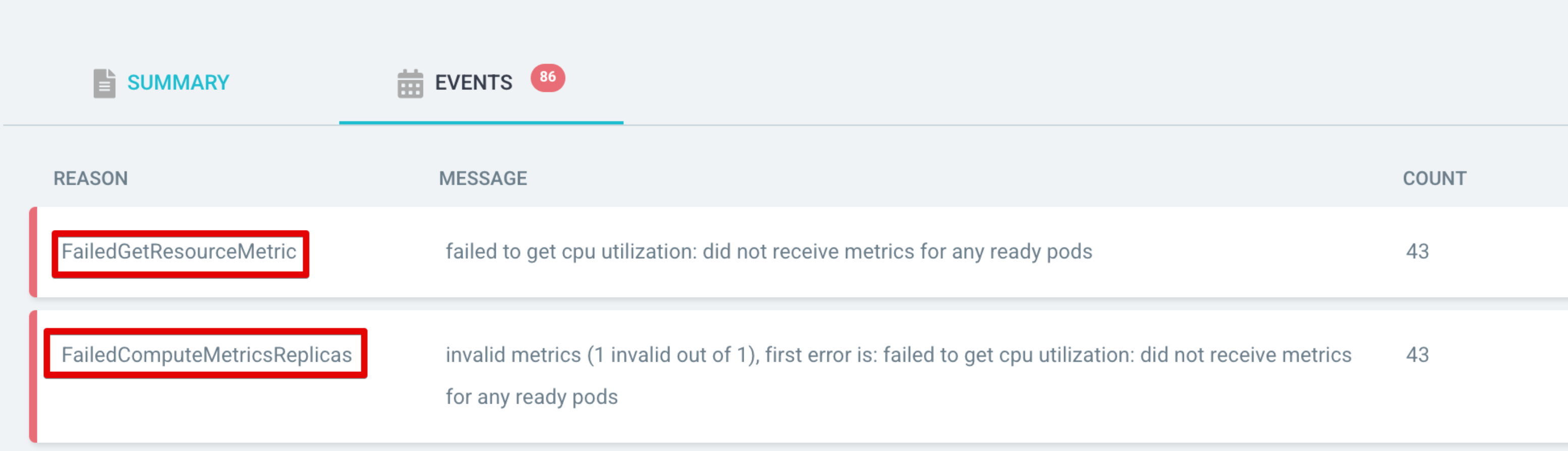
- Resolve Ref : https://argo-cd.readthedocs.io/en/stable/operator-manual/health/#custom-health-checks
data: resource.customizations: | cert-manager.io/Certificate: health.lua: | hs = {} if obj.status ~= nil then if obj.status.conditions ~= nil then for i, condition in ipairs(obj.status.conditions) do if condition.type == "Ready" and condition.status == "False" then hs.status = "Degraded" hs.message = condition.message return hs end if condition.type == "Ready" and condition.status == "True" then hs.status = "Healthy" hs.message = condition.message return hs end end end end hs.status = "Progressing" hs.message = "Waiting for certificate" return hs
4. HPA 적용 효과 및 사례
실제로 적용을 하고 나서는 다음의 수준으로 리소스 최적화를 할 수 있었습니다.
- Previous Resources

-
Current Resources

CPU는 약 2%, Memory는 6.1% 가량을 최적화 했습니다. 물론 100개중에 약 5개 정도만 선제적으로 적용을 한것이라 큰 효과는 없다고 생각할 수 있습니다. 하지만 이를 통해서 HPA의 장점을 취득하고 리소스를 최적화를 할 수 있다는 것을 배울 수 있었습니다.
5. 마치며..
HPA를 통해서 좀더 유연한 인프라를 제공할 수 있다는 것을 알게 됐습니다. 실제로 운영하면서 여러 차례 트래픽 스파이크시에 동작하는 것을 보고서 그 효과를 체험할 수 있었습니다. k8s를 통해서 셀프 힐링, 배포 자동화 등등의 큰 장점도 있지만 트래픽에 유연하게 대응할 수 있는 인프라를 제공하는 측면도 굉장히 효과적이라고 생각합니다.
포스팅을 마치도록 하겠습니다. 감사합니다.