[Kubernetes] K8S Cronjob Monitoring
안녕하세요? 정리하는 개발자 워니즈입니다. 이번 시간에는 Cronjob을 어떻게 모니터링하고 notification을 발송할지에 대해서 정리해보는 시간을 갖도록 하겠습니다.
개발팀에서는 주기적으로 수행하는 어플리케이션들에 대해서 Cronjob으로 구성해달라는 요청이 왔었고, 요구사항에 맞추어 하나의 Helmchart내에서 편리하게 구성할 수 있도록 구조를 잡았습니다.
1. Cronjob metric
Cronjob에 대한 메트릭을 먼저 확인하기로 했습니다.
- kube_job_complete : 실행 결과가 completed인 상태의 job 갯수
- kube_job_created : 실행 시간에 대한 Unix timestamp
- kube_job_failed : 실행 결과가 failed인 상태의 job 갯수
- kube_job_info : Job에 대한 정보
- kube_job_labels : k8s에서 prometheus로 변환된 label 정보
kube_job_complete{condition="false", job="test-kube-metric", job_name="test-1663646400", namespace="test", project="test-kube-metric", service="test-monitoring"}
0
kube_job_complete{condition="true", job="test-kube-metric", job_name="test-1663646400", namespace="test", project="test-kube-metric", service="test-monitoring"}
1
kube_job_complete{condition="unknown", job="test-kube-metric", job_name="test-1663646400", namespace="test", project="test-kube-metric", service="test-monitoring"}
0
kube_job_failed{condition="false", instance="lnlnklbd1502:31000", job="test-kube-metric", job_name="test-1663729200", namespace="test", project="test-kube-metric", service="test-monitoring"}
0
kube_job_failed{condition="true", instance="lnlnklbd1502:31000", job="test-kube-metric", job_name="test-1663729200", namespace="test", project="test-kube-metric", service="test-monitoring"}
1
kube_job_failed{condition="unknown", instance="lnlnklbd1502:31000", job="test-kube-metric", job_name="test-1663729200", namespace="test", project="test-kube-metric", service="test-monitoring"}
0
아래는 status에 대한 metric인데, 위에는 excution에 대해서 초점을 맞추었다면 아래는 phase(result)에 대해서 초점을 맞춘것입니다.
- kube_job_status_active : 구동중인 job에 대한 pod의 갯수
- kube_job_status_completion_time : job이 completed된 시간을 출력.
- kube_job_status_failed : 실패에 대한 이유와 Failed된 pod의 갯수
- kube_job_status_start_time : Job manager에 의해 job이 시작된 시간을 출력
- kube_job_status_succeeded : Completed된 pod의 갯수
kube_job_status_succeeded{job="test-kube-metric", job_name="test-1663642800", namespace="test", project="test-kube-metric", service="test-monitoring"}
1
kube_job_status_failed{job="test-kube-metric", job_name="test-1663729200", namespace="test", project="test-kube-metric", reason="BackoffLimitExceeded", service="test-monitoring"}
1
2. Cronjob dashboard
위에서 metric 확인을 한 이후에, 대시보드를 구성하기로 했습니다. Grafana에서 제공해주는 Dashboard를 찾아보았지만 너무 심플하기도했고 모니터링 하는데 활용하기는 어려운 부분이 있었습니다.
단순히 현재 수행되는 내용들에 대해서 가시성 있게 볼 수는 있었지만, 성공에 대한 이력, 실패에 대한 이력, 그리고 현재 수행중인 상태를 한눈에 확인하고 싶었습니다.
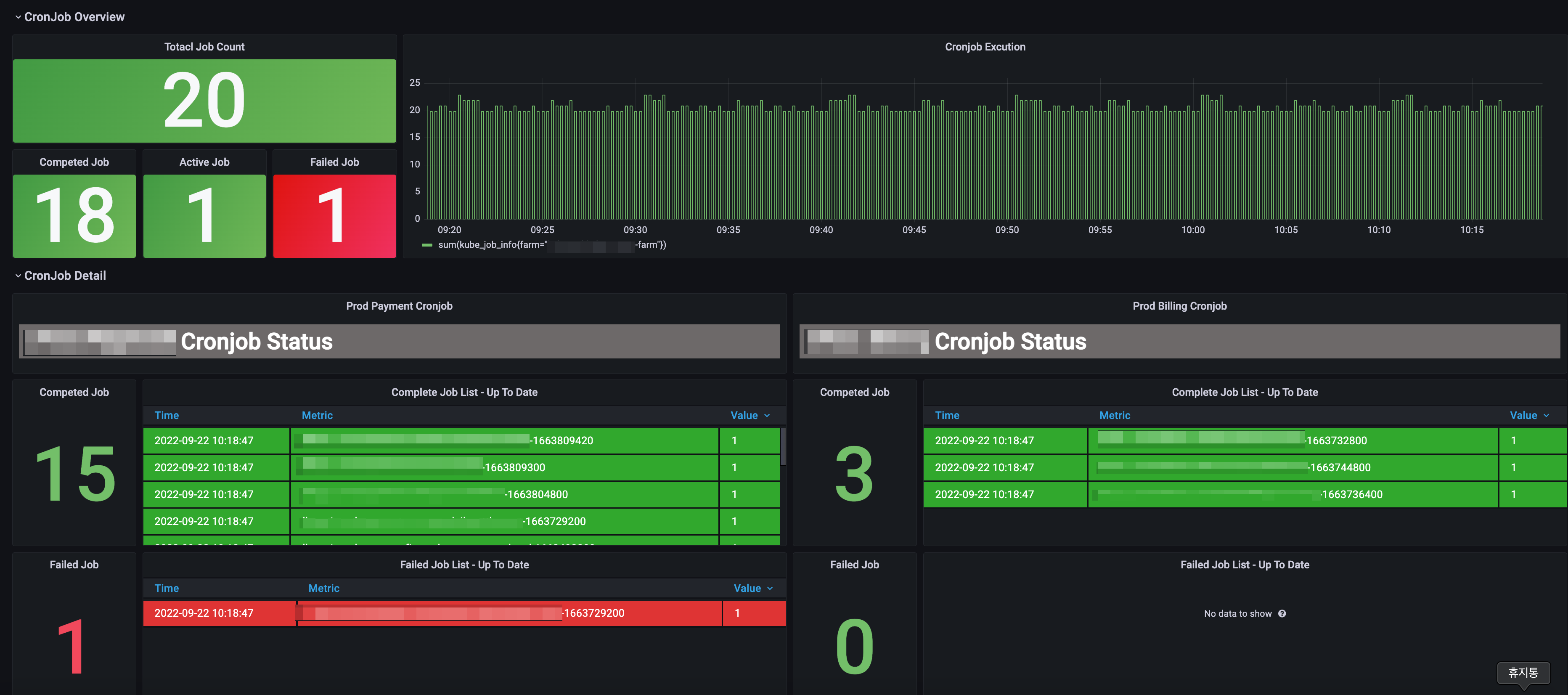
- 전체 수행중인 Overview 화면
- 현재 실행중인 Job의 갯수
- 현재 완료된 Job의 갯수
- 현재 실패한 Job의 갯수
위와 같이 구성을 하기로 하였고, 가급적 한눈에 봤을 때 실패한 이력만 보고도 현재 어디서 어느 Job에 문제가 생겼는지를 판별 할 수 있게 하고 싶었습니다.
전체 Job 정보
전체는 job_info 정보를 갖고 있는 모든 job들을 합하여 계산하였습니다.
sum(kube_job_info{farm="test-farm"})
완료된 Job 정보
job_complete를 통해서 complete이 true인것만 추출하여 계산하였습니다.
count(kube_job_complete{farm="test-farm"}==1)
수행중인 Job 정보
상태가 active 인것의 Job들을 합하여 계산하였습니다.
sum(kube_job_status_active{farm="test-farm"})
실패한 Job 정보
job_failed를 통해서 failed가 true인것만 추출하여 계산하였습니다.
count(kube_job_failed{farm="link-beta-kube-metric-farm"}==1)
구성간에 한가지 확인하는데 오래걸렸던 사항은 Job의 정보는 현재에 초점을 맞춰야 하다보니 과거의 기록들은 볼필요가 없습니다.
예를들어 A라는 Cronjob의 현재 수행상태를 보고싶은것이지 과거의 모든 정보들을 가져와서 표현을 하게 되면 정보가 많아져서 Dashboard의 역할을 할 수 없습니다.

Type을 Instant로 선택해 줌으로써, 현재 상태만을 가져올 수 있었습니다.
최종적으로 다음과 같은 화면에 대해서 구성을 하였습니다
- Overview
- A Service 에대한 Cronjob
- B Service 에 대한 Cronjob
3. Cronjob Alert 구성
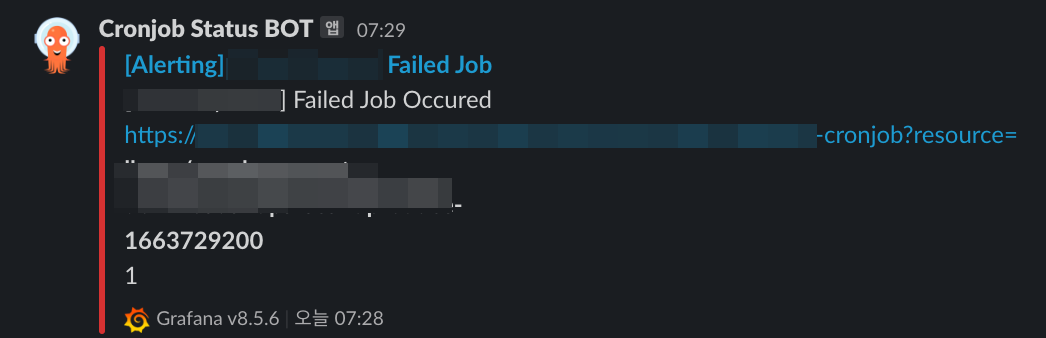
구성은 모두 됐으니, 이제 Alert를 구성하여, 개발팀에 알림 발송을 하기로 했습니다. Alert는 굉장히 심플하게 Failed인 상태가 1건이라도 발생시에 알림을 발송하기로했습니다.
실패한 Job 정보
kube_job_failed{farm="beta-farm", job_name=~".*-payment-.*"}==1
구성시 적용했던 job_failed와 한가지 달느것은 Metric Type을 Instant로 변경하여 최근에 발생한 건수가 존재한다면 바로 발송하는 방식으로 구성을 했습니다.
4. Cronjob 개선 내용
알림 발송까지는 모두 정상적으로 되었으나, 한가지 문제점을 확인했습니다. 만약 실패했던 Cronjob에서 수행된 Job이 성공을 했다면, 현재 구성에서는 실패한 History를 3개 유지하도록 설정했기 때문에, 실패 알람이 계속 발생을 하는 문제가 있었습니다.
아래처럼 A Cronjob의 최신이 성공을 했다고 하더라도, 실패 이력이 계속 남아있어 알람은 계속 발생하였습니다.
그래서 수동으로 실패한 이력들을 모두 제거하는 방식으로 했었습니다.
- A Cronjob
- 실패
- 실패
- ….
- 성공
이러한 방식을 개선하고자, 최신이 성공이라면 과거의 실패 History를 모두 제거하는 방식으로 코드를 개발하기로 했습니다.
결국, 하나의 Cronjob에서 최신의 수행이 성공(Completed)라면 과거의 실패(Failed)를 모두 제거하는 방식으로 개발을 수행했고, 정상적으로 동작을 하였습니다.
#0. assign variable
LAST_JOB_NAME=""
LAST_CRON_NAME=""
LAST_STATUS=""
NEXT_JOB_NAME=""
NEXT_CRON_NAME=""
NEXT_STATUS=""
LOOPCOUNT=1
DEL_JOB_ARR=()
ARR=()
checkLastStatus() {
if [[ "$LAST_STATUS" == "Complete" && ${#DEL_JOB_ARR[@]} -gt 0 ]]; then
### Failed -> pass && celar DEL_JOB_ARR
CMD=`kubectl delete job "${DEL_JOB_ARR[@]}"`
echo $CMD
fi
### Complete -> delete all value from array
DEL_JOB_ARR=()
}
#1. read line
#IFS=$'\n' read -ra ARR -d $'\0' <<< "$TEXT"
ARR=`kubectl get job -o json | jq -r '.items[] | .metadata.name + ":" + (select ( .status | has("conditions")) | .status.conditions[] | select(.status == "True") .type )'`
LASTCOUNT=${#ARR[@]}
for line in ${ARR[@]}
do
#1. start loop
if [[ $LOOPCOUNT -eq 1 ]]; then
LAST_JOB_NAME=`echo $line | awk -F: '{print $NR}'`
LAST_STATUS=`echo $line | awk -F: '{print $NF}'`
LAST_CRON_NAME=`echo ${LAST_JOB_NAME::-11}`
LOOPCOUNT=2
continue
fi
#2. assign variable -> last, next
NEXT_JOB_NAME=`echo $line | awk -F: '{print $NR}'`
NEXT_STATUS=`echo $line | awk -F: '{print $NF}'`
NEXT_CRON_NAME=${NEXT_JOB_NAME::-11}
#3. compare
if [[ "$LAST_CRON_NAME" == "$NEXT_CRON_NAME" ]]; then
### next == last then check last status
### last -> array
DEL_JOB_ARR=("${DEL_JOB_ARR[@]}" "$LAST_JOB_NAME")
else
### next != last then check last status
checkLastStatus
fi
#4. update laste value for next
LAST_JOB_NAME=$NEXT_JOB_NAME
LAST_STATUS=$NEXT_STATUS
LAST_CRON_NAME=$NEXT_CRON_NAME
#5. increase loop count
((LOOPCOUNT=LOOPCOUNT+1))
#6. last loop
if [[ $LOOPCOUNT -eq $LASTCOUNT+1 ]]; then
checkLastStatus
fi
done
5. 마치며…
Cronjob에 대한 Reference가 상당히 없는 상황에서 하나씩 구성해나가면서 현재 작성하는 것들이 다른사람의 Reference가 될 수도 있겠구나라는 생각을 했습니다.
Grafana에서도 제공하는 Dashboard만으로는 뭔가 완성도가 떨어진다고 생각이 들었는데 이러한 부분들도 오픈소스로 기여할 수 있는 방법이 있을지도 한번 찾아보려고 합니다. 제가 작성한 Dashboard를 다른사람들도 가져다가 Customizing하면서 발전시켜주면 너무 좋을 것 같습니다.