[DevOps] logstash S3 로그 수집
[DevOps] logstash S3 로그 수집
안녕하세요? 정리하는 개발자 워니즈입니다. 오랜만에 글을 작성하려니, 어떤 내용부터 어떻게 쓸지 고민을 하다가 최근들어서 하고있는 내용을 정리하기로 했습니다.
오늘은 Logstash라는 주제로 정리를 해볼까 합니다. 로그스태시는 원천 데이터 파일로부터 특정 처리를 수행하고 그 결과에 대해서 적재해주는 구조입니다.
이전에 필자가 아래의 내용으로 포스팅을 한적이 있습니다. 로그를 수집하고 해당 내용을 분석하는 대시보드를 작성하는 내용으로 전체적으로 ELK 스택이 어떻게 동작하는지를 보았습니다.

이번에는 Logstash에 좀더 집중해서 보려고 합니다. 로그스태시를 사용하기 위해서는 기존의 docker-elk compose 파일을 통해서 올리도록 하겠습니다.
1. Logstash 설치 방법
기본적으로 설명드리는 내용은 docker daemon이 설치된 VM에서 하는 내용입니다. elk docker-compose 내용중에 logstash만 남기고, 내용을 모두 삭제하여 다음과 같이 만들어줄 예정입니다 .
1-1. 폴더 tree
├── docker-compose.yml
├── docker-stack.yml
├── extensions
│ ├── apm-server
│ │ ├── apm-server-compose.yml
│ │ ├── config
│ │ │ └── apm-server.yml
│ │ ├── Dockerfile
│ │ └── README.md
│ ├── curator
│ │ ├── config
│ │ │ ├── curator.yml
│ │ │ └── delete_log_files_curator.yml
│ │ ├── curator-compose.yml
│ │ ├── Dockerfile
│ │ ├── entrypoint.sh
│ │ └── README.md
│ ├── logspout
│ │ ├── build.sh
│ │ ├── Dockerfile
│ │ ├── logspout-compose.yml
│ │ ├── modules.go
│ │ └── README.md
│ └── README.md
├── LICENSE
├── logstash
│ ├── config
│ │ └── logstash.yml
│ ├── data
│ │ └── plugins
│ │ └── inputs
│ │ └── s3
│ │ ├── sincedb_1d7494114df033e1769f7a13894328e3
│ │ └── sincedb_c134b2a92a773825e5ce19bfb9ee390a
│ ├── Dockerfile
│ └── pipeline
│ └── logstash.conf
├── README.md
└── ts
└── es.log
기본적으로 docker-elk 스택을 다운받아서 불필요한 내용은 지우는 방식으로 진행했습니다.
위에 깃헙 폴더를 그대로 다운받으면, elk 내용이 안에 모두 있는데 불필요한 파일들은 삭제 했습니다. 또한, docker-compose.yaml 파일중에서도 elasticsearch와 kibana에 대한 내용은 모두 삭제를 했습니다.
그리고 실제로 건드리게 되는 부분은 logstash > pipeline > logstash.conf 파일 입니다. 여기서 필요한 configure작업을 진행하고, 해당 내용을 컨테이너로 올린 logstash에서 사용하도록 하는 내용입니다.
2. Logstash conf파일 정리
로그스태시는 기본적으로 inpu, filter, output으로 이루어져있습니다.
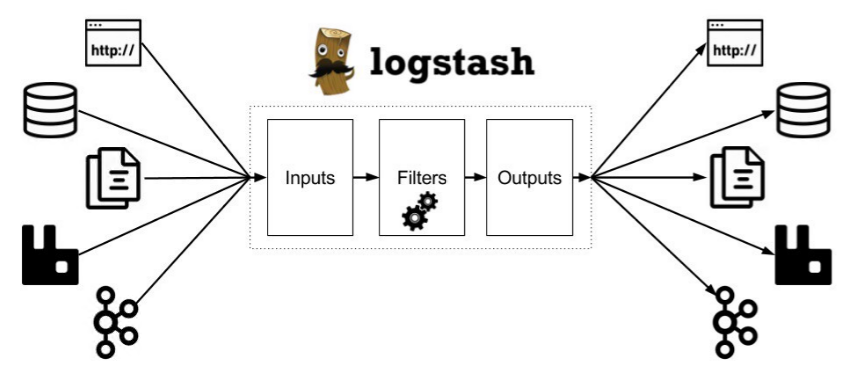
좌측의 원천 데이터로부터 내용을 Logstash가 Pulling을 통해서 수집하고 Filter라는 영역에서 연산처리를 진행한다음에 Output으로 데이터를 전송하게 됩니다.
지금 필자가 만들어 가려는것은 다음과 같은 내용입니다.

AWS LB의 로그 수집을 켜두게 되면, S3에 해당 내용이 gz으로 압축되어 기록이 되게 됩니다. 그러면, 해당 S3 파일을 읽어서 Logstash 에서 연산처리를 진행하고 ElasticSearch로 수집을 하게 됩니다. 그렇게 한 후, Kibana를 통해서 Visualize를 수행하게 됩니다.
2-1. logsatsh.conf 내용
- Input
input {
s3 {
access_key_id => "{개별 key id}"
secret_access_key => "{개별 access key}"
region => "ap-northeast-2"
bucket => "p6-prd-ap-alb-accesslog"
type => "s3_ap_access"
}
s3 {
access_key_id => "{개별 key id}"
secret_access_key => "{개별 access key}"
region => "eu-central-1"
bucket => "p6-prd-eu-alb-accesslog"
type => "s3_eu_access"
}
}
input은 크게 2개로 구성이 되어서, AP지역과 EU지역으로 수집을 하게 됩니다.
- filter
filter {
grok {
match => [ "message", '%{NOTSPACE} %{TIMESTAMP_ISO8601:inner_timestamp} %{NOTSPACE:loadbalancer} %{IP}:%{NUMBER} (%{IP}:%{NUMBER}) %{NUMBER} %{NUMBER} %{NUMBER} %{NUMBER:elb_status_code:int} %{NUMBER:backend_status_code:int} %{NUMBER:received_bytes:int} %{NUMBER:se
nt_bytes:int} \"%{WORD:method} %{URIPROTO:uri_proto}://(?:%{USER:user}(?::[^@]*)?@)?(?:%{URIHOST:uri_domain})?%{URIPATH:url_path}%{URIPARAM:url_params}? HTTP/%{NOTSPACE}\" \"%{DATA:agent}\"' ] }
#url parameter 변환
mutate { gsub => ["url_params","\?","" ] }
mutate { split => {"url_params" => "&" } }
ruby {
code => "
#변수 선언
pathArr = event.get('url_path')
paramArr = event.get('url_params')
#siteCode 처리
parameter = []
if pathArr.length > 1
event.set('site_code', pathArr.split('/')[1])
end
#parameter 처리
if !paramArr.nil? and paramArr.length > 1
paramArr.each do |item|
parameter.push(item.split('=')[0])
end
end
event.set('parameter', parameter)
"
}
date { match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]}
mutate { remove_field => [ "message","url_params"]}
}
사실 필자가 이번 포스팅에 가장 강조하는 부분은 filter 입니다. 이 내용은 아래에서 하나씩 풀어서 정리를 하도록 하겠습니다. 간단하게 말하면, S3로부터 온 원데이터(message)를 ruby 스크립트를 통해서 원하는 데이터를 자르는 내용입니다.
- output
output {
stdout {
codec => rubydebug
}
if "p6_s3_ap_access" in [type] {
elasticsearch {
hosts => ["{elasticsearch IP}"]
index => "p6_s3_ap_access-%{+YYYYMMdd}"
}
} else if "p6_s3_eu_access" in [type] {
elasticsearch {
hosts => ["{elastciserach IP}"]
index => "p6_s3_eu_access-%{+YYYYMMdd}"
}
}
}
output 같은 경우는 elasticsearch로 넣을 수 있도록 셋팅을 합니다.
3. logstash.conf 분석
grok {
match => [ "message", '%{NOTSPACE} %{TIMESTAMP_ISO8601:inner_timestamp} %{NOTSPACE:loadbalancer} %{IP}:%{NUMBER} (%{IP}:%{NUMBER}) %{NUMBER} %{NUMBER} %{NUMBER} %{NUMBER:elb_status_code:int} %{NUMBER:backend_status_code:int} %{NUMBER:received_bytes:int} %{NUMBER:se
nt_bytes:int} \"%{WORD:method} %{URIPROTO:uri_proto}://(?:%{USER:user}(?::[^@]*)?@)?(?:%{URIHOST:uri_domain})?%{URIPATH:url_path}%{URIPARAM:url_params}? HTTP/%{NOTSPACE}\" \"%{DATA:agent}\"' ] }
grok 같은 경우는 disect plugin입니다. 들어온 포맷을 하나의 인자로 인식하고 지정된 format에 맞게 하나씩 요소를 잘라줍니다.
실제로 들어오는 문자열을 확인해보겠습니다.
https 2020-09-03T23:59:57.034675Z app/ALB-P6-PRD-EU-LIVE/048d50b66292f86e xx.xxx.xx.xxx:48579 xx.x.xxx.xx:30301 0.000 0.012 0.000 200 200 3995 290627 "GET https://www.samsung.com:443/us/galaxybooks/?cid=smp-mktg-stc-mob-us-facebookinstagram-na-08032020-123197-979858-278640164-135765666&dclid=CNr_wOSYzusCFcq1fgodukAChQ HTTP/1.1" "Mozilla/5.0 (Linux; Android 8.1.0; LM-X212(G) Build/OPM1.171019.026; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/81.0.4044.138 Mobile Safari/537.36
위의 내용이 원본 데이터인 message로 인식이 되게 되고, 하나씩 disect를 진행합니다.
아래의 내용에 맞춰서 grok pattern이 정의 됩니다.
%{NOTSPACE}
%{TIMESTAMP_ISO8601:inner_timestamp}
%{NOTSPACE:loadbalancer}
%{IP}:%{NUMBER}
(%{IP}:%{NUMBER})
%{NUMBER}
%{NUMBER}
%{NUMBER}
%{NUMBER:elb_status_code:int}
%{NUMBER:backend_status_code:int}
%{NUMBER:received_bytes:int}
%{NUMBER:sent_bytes:int}
\"%{WORD:method} %{URIPROTO:uri_proto}://(?:%{USER:user}(?::[^@]*)?@)?(?:%{URIHOST:uri_domain})?%{URIPATH:url_path}%{URIPARAM:url_params}? HTTP/%{NOTSPACE}\"
\"%{DATA:agent}\"
https
2020-09-03T23:59:57.034675Z
app/ALB-P6-PRD-EU-LIVE/048d50b66292f86e
xx.xxx.xx.xxx:48579
xx.x.xxx.xx:30301
0.000
0.012
0.000
200
200
3995
290627
"GET https://www.samsung.com:443/us/galaxybooks/?cid=smp-mktg-stc-mob-us-facebookinstagram-na-08032020-123197-979858-278640164-135765666&dclid=CNr_wOSYzusCFcq1fgodukAChQ HTTP/1.1"
"Mozilla/5.0 (Linux; Android 8.1.0; LM-X212(G) Build/OPM1.171019.026; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/81.0.4044.138 Mobile Safari/537.36"
위의 깃헙에 들어가보면, grok 요소의 pattern을 정의를 해두었습니다. 하나씩 맞춰서 가져와서 사용하면 됩니다. 실제 들어오는 내용과 grok pattern을 맞춰서 보기 편하게 위와 같이 두었습니다.
- request url 처리
"%{WORD:method} %{URIPROTO:uri_proto}://(?:%{USER:user}(?::[^@]*)?@)?(?:%{URIHOST:uri_domain})?%{URIPATH:url_path}%{URIPARAM:url_params}? HTTP/%{NOTSPACE}\"
위의 부분이 중요한데, request url 같은 경우는 ” “ 와 같이 들어오기 때문에 이스케이프 처리를 좌우측으로 해주었습니다. 그리고 다시 url내부에서도 domain + path + params로 disect 하도록 정의를 해두었습니다.
- parameter 처리
mutate { gsub => ["url_params","\?","" ] }
mutate { split => {"url_params" => "&" } }
parameter에 대한 처리를 위해서는 위와 같이 처리를 진행했습니다. ? 이후에 오는 문자열은 parameter로 인식하게 해두었고, 여러개가 이어서 &문자열이 오는부분에 대해서 split을 사용하여 잘라두었습니다.
ruby {
code => "
#변수 선언
pathArr = event.get('url_path')
paramArr = event.get('url_params')
#siteCode 처리
parameter = []
if pathArr.length > 1
event.set('site_code', pathArr.split('/')[1])
end
#parameter 처리
if !paramArr.nil? and paramArr.length > 1
paramArr.each do |item|
parameter.push(item.split('=')[0])
end
end
event.set('parameter', parameter)
"
}
그리고 중요한 내용이 바로 위의 내용입니다. 하고자 하는것은 parameter로 들어온 내용을 key만 elastic에 넣어서 보고 싶은 내용입니다.
url_path를 위에서 받게 되면, /us/galaxybooks/ 여기까지 받아지게 됩니다. 그리고 해당 내용에서 제일 앞의 내용을 가져와서 site_code로 넣는 내용이 추가 되어있습니다.
url_params를 위에서 받게 되면, array형태로 받아지고, ruby 스크립트를 통해서 array를 하나씩 돌면서, = 문자열로 잘라서, key값만 가져오도록 처리를 하고 있습니다. 그리고 최종적으로 parameter로 넣는 내용이 추가 되어있습니다.
그리고 최종적으로 elasticsearch로 넣는 작업이 output에 명시가 되어있습니다.
4. kibana에서 데이터 확인

키바나의 discover라는 탭을 통해서 위와 같이 지정해 놓은 index pattern에 따라서 확인이 가능합니다. S3에서의 access log를 계속해서 적재 하고 있는것을 볼 수 있습니다 .
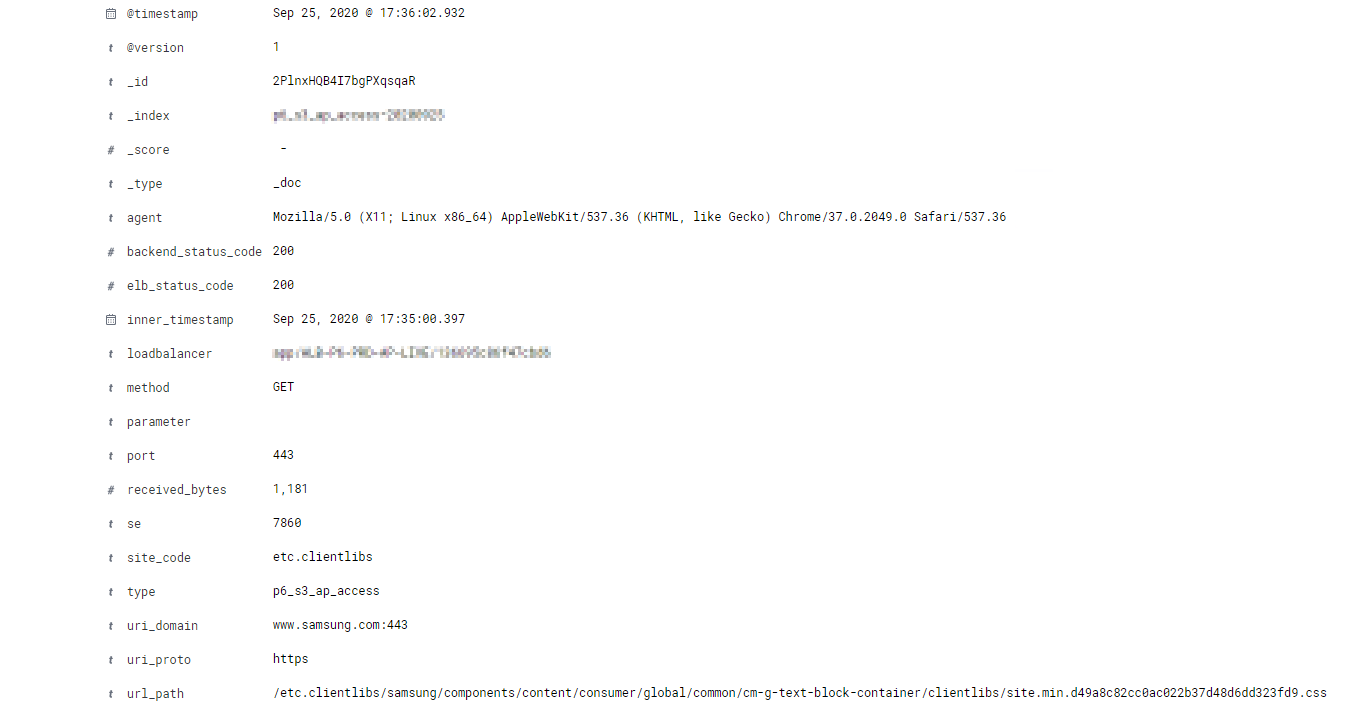
하나의 데이터를 확인해보면, 위와 같이 위에서 disect 했던 내용이 모두 정상적으로 적재 되어있는 것을 볼 수 있습니다.
parameter같은 경우는 없게 되면 비어있는 값이 노출 됩니다.
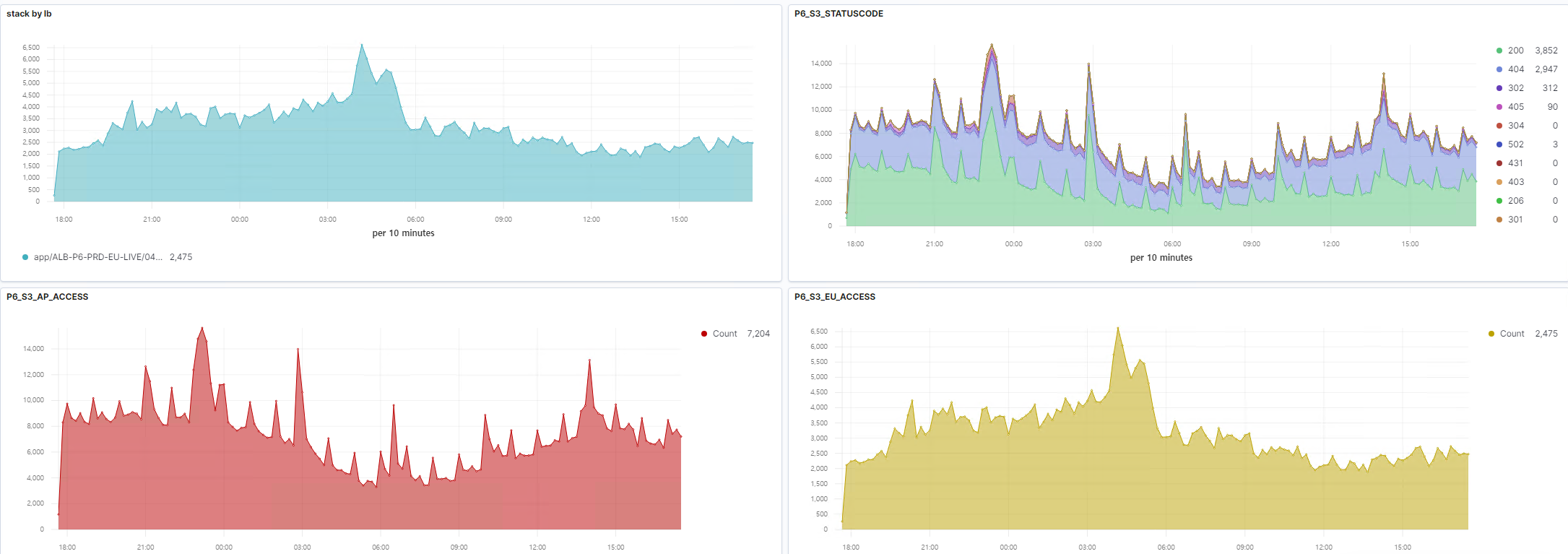
최종적으로 위와 같이 대시보드로 작성을 해볼 수 가 있습니다. 이렇게 하게 되면, 외부 트래픽에 대해서 어떻게 들어오는지를 한눈에 볼 수 있습니다.
5. 마치며..
이번 포스팅은 로그스태시의 사용법중 루비스크립트를 통해서 작성하는 방법에 대해서 알아보았습니다. 루비스크립트로 가져온 원본 데이터를 적재 적소에 활용 할 수 있게끔 filter 작업을 진행했습니다. 그리고 elastic에 데이터를 적재하고 kibana로 표현을 해보았습니다.
다음 이시간에는 kibana의 visualize부터 dashboard 작성법에 대해서 정리를 해보도록 하겠습니다.