[Linux] Load Average와 시스템 부하
[Linux] Load Average와 시스템 부하
안녕하세요? 정리하는 개발자 워니즈입니다. 이번시간에는 리눅스의 Load Average에 대해서 정리하는 시간을 갖도록 하겠습니다.
필자의 아는 지인분이 저에게 물어본적이 있습니다.
지인 : TOP 명령어를 치고 나오는 Load Average가 뭘 의미하는지 알아요?
필자 : 로드 평균.... 로드가 걸린다....모르겠습니다.
사실 정의는 간단합니다. 이전에 정리해놓은 포스팅에서 R, D상태에 있는 job들의 갯수라고 보시면 됩니다. 즉, 현재 진행중인 job이거나 아니면 D상태로 I/O와 같은 요청을 하고 잠시 대기 상태에 빠져있는 job들이 갯수 입니다.
얼마나 많은 프로세스가 실행 중 혹은 실행 대기중이냐를 의미하는 수치입니다. Load Average가 높다면 많은 수의 프로세스가 실행 중이거나 I/O 등을 처리하기 위한 대기 상태에 있다는 것이며, 낮다면 적은 수의 프로세스가 실행 중이거나 대기 중이라는 의미입니다.
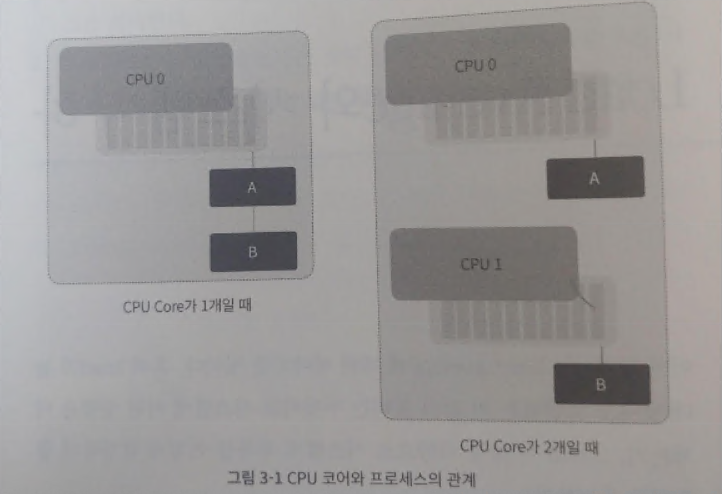
위에 보시는 그림에서 각각 Load Average는 2에 가까운 수치가 나올 것입니다.
하지만, Core의 갯수에 따라 그 의미가 달라집니다. 왼쪽 그림은 Run Queu에 두 개의 프로세스가 있으며 이 경우 한 번에 하나만 실행되기 때문에 나머지 하나의 프로세스는 대기 상태에 있을 수 밖에 없습니다.
오른쪽 그림은 Run Queue에 두 개의 프로세스가 있지만 서로 다른 CPU에 있기 때문에 A와 B는 동시에 실행 될 수 있습니다. 현재 시스템에서 처리 가능한 만큼의 프로세스가 있다는 것입니다.
1. CPU Bound vs I/O Bound
앞선 Load Average의 개념에 대해서 정리를 했습니다. 서버에서 부하가 걸리는 원인은 크게 2가지를 꼽습니다.
- CPU 부하
- I/O 부하
CPU 부하가 높은 경우는 서버에서 실행되고 있는 프로그램 자체의 연산량이 많은 경우나 프로그램에 오류등이 발생하는 경우 입니다. 이러한 경우는 대게 Source Code 레벨에서 수정이 가능합니다. 오류 제거, 알고리즘의 시간, 공간 복잡도를 개선하여 대응 할 수 있습니다.
I/O 부하가 높은 경우는 서버에서 실행되고 있는 프로그램의 I/O가 많거나, DB나 하드디스크 등의 저장장치로의 접근이 많아 스왑이 발생하는 경우가 대부분입니다. 저장장치나 하드디스크로의 입출력이 빈번하게 발생하는 경우, 메모리 증설하는 방법으로 대응할 수 있습니다.
메모리 증설로 해결할 수 없는 경우 데이터 자체를 분산 (샤딩이나 파티셔닝) 하거나 캐시서버등을 도입하는 방안을 고려해 볼 수 있습니다.
부하를 일으키는 프로세스는 크게 두가지 종류로 나눌 수 있습니다.
- nr_running
- nu_uninterruptible
두 종류의 부하 프로세스는 같은 Load Average를 보여준다고 해도 사실 일으키고 있는 부하는 전혀 다른 부하이다.
2. vmstat으로 부하의 정체 확인하기
Load Average 값은 시스템에 부하가 있다는 것을 알려주지만 구체적으로 어떤 부하인지는 알 수 없습니다. 어떤 부하가 일어나는지에 대한 정보는 vmstat을 통해서 확인 할 수 있습니다.
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 293156 134388 21696656 0 0 30 76 0 1 3 2 94 0 0
r: The number of processes waiting for run time.
b: The number of processes in uninterruptible sleep.
r은 실행되기를 기다리거나 현재 실행되고 있는 프로세스의 갯수를, b는 I/O를 위해 대기열에 있는 프로세스의 갯수를 말합니다. 즉 각각이 nr_running, nr_uninterruptible을 의미한다고 볼 수 있습니다.
3. Load Average가 보고하는 부하의 정체
시스템 부하의 원인이 대부분의 경우 CPU나 I/O에 있음을 나타내고 있습니다. Load Average로 시스템에 과부하가 걸리고 있다는 사실을 알게된 후에는, 한단계 더 나아가 CPU와 I/O중 어떤 부분에서 부하가 걸리는지를 조사해야 합니다.
CPU는 사용자 모드와 시스템 모드로 나뉘어집니다.
사용자 모드는 사용자 프로그램이 동작할 떄의 CPU 모드이며 시스템 모드는 커널이 동작할 때의 CPU 모드 입니다.
15시 20분 01초 CPU %user %nice %system %iowait %steal %idle
15시 30분 01초 all 0.62 0.00 0.10 0.00 0.00 99.28
15시 40분 01초 all 0.75 0.00 0.14 0.00 0.00 99.11
15시 50분 01초 all 0.63 0.00 0.11 0.00 0.00 99.26
16시 00분 01초 all 0.64 0.00 0.13 0.00 0.00 99.23
16시 10분 01초 all 0.65 0.00 0.15 0.00 0.00 99.20
16시 20분 01초 all 0.63 0.00 0.11 0.00 0.00 99.26
16시 30분 01초 all 0.66 0.00 0.11 0.00 0.00 99.23
16시 40분 01초 all 0.65 0.00 0.12 0.00 0.00 99.23
16시 50분 01초 all 0.65 0.00 0.13 0.00 0.00 99.22
17시 00분 01초 all 0.64 0.00 0.11 0.00 0.00 99.25
17시 10분 01초 all 0.66 0.00 0.14 0.00 0.00 99.20
17시 20분 01초 all 0.69 0.00 0.19 0.00 0.00 99.12
17시 30분 01초 all 0.66 0.00 0.13 0.00 0.00 99.20
17시 40분 01초 all 0.65 0.00 0.14 0.00 0.00 99.21
17시 50분 01초 all 0.65 0.00 0.13 0.00 0.00 99.21
sar명령어를 사용하면 부하를 시킨 경과 별로 확인할 수 있어 매우 편리합니다. 위의 결과에서 %user는 사용자 모드에서의 CPU 사용률을 나타내며 %system은 시스템 모드에서의 CPU 사용률을 나타냅니다.
%iowait 이 높은 상태이면 I/O가 시스템 부하의 원인이 될 수 있으며, 이때에는 I/O 관련하여 더 자세한 지표인 메모리 사용률이나 프로세스별 스왑 발생 상황등을 더 자세히 살펴본 후 적절히 대응할 수 있습니다.
4. 마치며…
사실 위의 내용을 정리하면서 2가지의 측정을 사용하였습니다. vmstat과 sar 입니다. 어쩃든 결론을 내리자면 부하의 원인에 대해서 어떠한 명령어가 됐든 확인을 해보고 판단을 내리자는 것을 배웠습니다. 크게 2가지 (cpu bound, i/o bound)에 대해서 분석을 수행 한 후, 원인을 일으키는 것이 어떤것인지를 접근하면 훨씬 편해지는것 같습니다.
다음 이시간에는 메모리의 대한 내용을 정리하고자 합니다. 많은 기대 부탁드립니다.