[Kubernetes] Autoscaling 사용하기
[Kubernetes] Autoscaling 사용하기
안녕하세요? 정리하는 개발자 워니즈입니다. 이번시간에는 쿠버네티스 autoscaling 기능에 대해서 정리를 해보도록 하겠습니다. 필자가 지금까지 구축해온 쿠버네티스 환경은 단순히 POD를 배포를 하고 쿠버네티스가 알아서 자가치유(self-healing)을 하는 단계까지는 되었습니다.
하지만, 트래픽이 늘어나거나 줄었을때 시스템 자원의 임계치에 다다랐을 경우 유동적으로 pod를 증설하고 감소시키는 내용이 추가되어있지 않았습니다.
그래서 이번에는 쿠버네티스의 HPA(horizontal pod autoscailing)의 object를 신규로 생성하고 적용해보는 포스팅을 해보겠습니다.
지난 글들은 아래를 참고 해주시면 됩니다.
- 쿠버네티스 1편 : 설치 가이드
- 쿠버네티스 2편 : pod
- 쿠버네티스 3편 : service
- 쿠버네티스 4편 : deployment
- 쿠버네티스 5편 : pod 설정
- 쿠버네티스 6편 : 배포 전략
- 쿠버네티스 7편 : volume
- 쿠버네티스 8편 : daemonset
- 쿠버네티스 9편 : 테라폼을 통한 클러스터 구성
- 쿠버네티스 10편 : eks에서 volume 사용하기
- 쿠버네티스 11편 : helm
- 쿠버네티스 12편 : helm chart template
- 쿠버네티스 13편 : helm deploy
- 쿠버네티스 14편 : fluentd를 통한 log수집
- 쿠버네티스 15편 : chartmuseum
- 쿠버네티스 16편 : 배포툴(ArgoCD 설치방법/사용법)
- 쿠버네티스 17편 : 배포툴(ArgoCD 구성/알람)
- 쿠버네티스 18편 : 쿠버네티스 Autoscailing
- 쿠버네티스 19편 : 쿠버네티스 로깅 아키텍처
#쿠버네티스가 CPU 자원에 대한 사용량을 계산하는 방식
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
주기적으로 Pod의 자원 사용을 체크하고, 특정 시간을 두고 scale에 대해서 in/out이 이루어집니다. 이는 kube-controller-manager가 담당합니다.
1. Metric-Server 설치 하기
쿠버네티스를 설치하게 되면 자원에 대한 모니터링이 필요하다. 과거에는 Heapster를 이용했지만 현재는 Deprecated된 상태이고 이것을 대체하는 것이 Metric Server 입니다.
쿠버네티스 v1.11부터 heapster가 deprecated 되었습니다 (자세한 내용은 문서를 참고 바랍니다.) 그래서 HPA(horizontal pod autoscaler)나 kubectl top 명령어를 사용하라면 metrics-server를 사용해야 합니다.
Metric Server를 설치하게 되면 Kubernetes의 컴포넌트들에 대한 자원 모니터링이 가능해지며 이것을 이용해서 Autoscaling에도 사용이 가능해집니다.
1-1. 설치파일 다운로드
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
설치파일은 다운받고, 바로 apply를 해도 되지만, 갑자기 안의 내용들이 하나하나 궁금해지기 시작했습니다. 그래서 하나씩 파해쳐보기로했습니다 .
1-2. metric server component 분석
#metric-server SA 생성
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
#클러스터 롤 생성
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
#SA - 클러스터롤 바인딩
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
#정확히는 모르겠지만.. auth관련된 내용을 클러스터와 namespace에서 인증되도록 처리를 한것같습니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
위의 내용이 반영되면, metric server에서 API통신을 통해서 각 metric들을 수집하는 것이 가능해집니다.
1-3. TLS 수정
Metric Server 를 설치할때에 주의해야 할 것은 Kube API 서버와의 통신에서 사용할 TLS 를 수정하는 것이다. Metric Server 는 Public TLS 를 기본으로 하지만 Kube API 는 Kube 자체의 TLS 를 사용하기 때문에 그냥 설치하면 문제가 된다.
#TLS 관련 arg수정
$ vim components.yaml
....
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
....
1-4. Deploy
이제 이것을 Deploy 해준다. Kubernetes 에서는 설치라는게 없다. 모두 다 pods 로 다 올라가기 때문에 Deploy 라고 한다.
$ kubectl apply -f components.yaml
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server unchanged
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
1-5. 메트릭 수집 확인
[root@ip-10-0-134-183 ~ ]# k top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-10-0-134-195.ap-northeast-2.compute.internal 221m 11% 5343Mi 90%
ip-10-0-144-171.ap-northeast-2.compute.internal 126m 6% 2515Mi
2. HPA 사용하기
오토스켈링을 사용하기 위해서 설정을 해보도록 하겠습니다.
2-1. HPA YAML 작성
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: kubernetes-simple-app-hpa
namespace: dev-web
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: kubernetes-simple-app
targetCPUUtilizationPercentage: 30
위의 내용에서 보듯이, 중요한 부분은 spec에 명시 되어있습니다.
#replica 갯수의 범위에 대한 내용입니다.
maxReplicas: 10
minReplicas: 1
#어떤 deployment에 대해서 적용할지를 선택합니다.
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: kubernetes-simple-app
#어떤 resource에 대해서 타겟을 갖을지 정합니다.
targetCPUUtilizationPercentage: 30
2-2. 테스트
jmeter를 통해서 부하를 발생시켜줍니다. jmeter에 대한 내용은 추후에 포스팅을 하도록 하겠습니다.
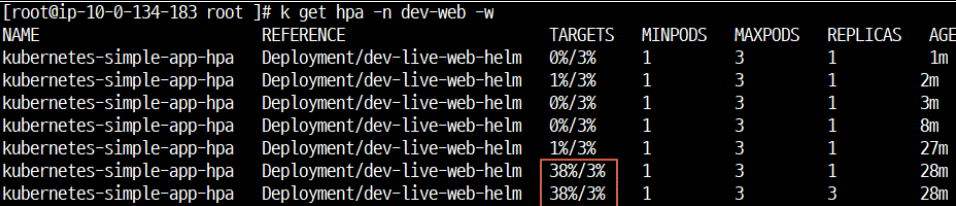
-> dev-live-web-helm 에서 분당 측정시 cpu 38%로 증가

-> pod 증설
jmeter 중단을 합니다.

-> dev-livve-web-helm 에서 5분당 측정시 cpu 0%로 감소
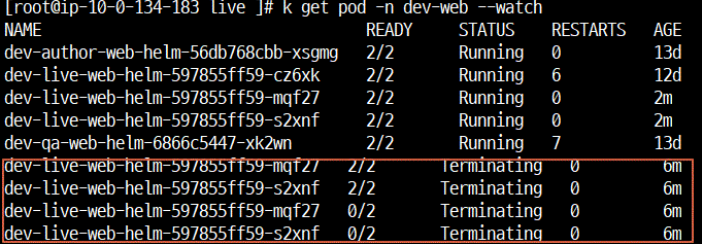
-> pod 감소
아직 세밀한 설정( 증설,감소 유지 시간) 에 대한 셋팅없이 default로 설정했습니다.
(default : 1분간 cpu임계치 지속되면 증설 & 5분간 cpu 임계치 아래로 지속되면 감소)
3. 마치며..
확실히 hpa를 통해서 resource에 대해서 좀더 유동적으로 서비스 제어를 할 수 있다는 부분에서 쿠버네티의 장점이 극대화 되는것을 느꼈습니다. 이전 같았으면, 증설 시나리오에 맞춰서 VM을 띄우고 안에 Native로 어플리케이션을 설치하고 설정 잡아주고 구동하는데까지 정말 많은 시간이 소요가 되었습니다. 하지만, 쿠버네티스를 통해서 좀더 유동적으로 서비스를 제어할 수 있었고, 이 모든것을 자동화 해놓음으로써 운영자에게는 굉장히 큰 장점으로 다가왔습니다.
다음 이시간에는 Cluster Autoscale에 대해서 정리를 해보도록 하겠습니다.