[DevOps] ELK를 활용한 로그 분석
안녕하세요? 정리하는 개발자 워니즈입니다. 이번시간에는 ELK를 활용한 웹서버 로그 분석에 대해서 알아보는 시간을 갖도록 해보겠습니다.
필자가 운영하는 프로젝트에서는 Nginx(IDS – Internet Detection Server) 와 Apache(웹서버) – WAS 서버의 구성으로 이루어져있습니다.
Apache에서는 whitelist된 URL query string 에 대해서만 캐시를 남기고 그외에는 WAS까지 접속하여 가져오는 구성으로 되어어 있습니다. (식별된 파라미터에 대해서는 캐싱된 페이지를 보여주기 위함 입니다.)
그러다보니, 비식별된 파라미터들의 접속량이 증가하면 WAS 서버에 부하를 주게 되어 이를 모니터링 할 수 있는 프로세스를 생각해봤습니다.
그러던중 ELK를 알게 되었고, filebeat와 logstash를 적절하게 이용하면 로그분석을 통하여 비식별 파라미터를 추출해 낼 수 있을 것이라고 생각했습니다.
1. 로그 수집 프로세스
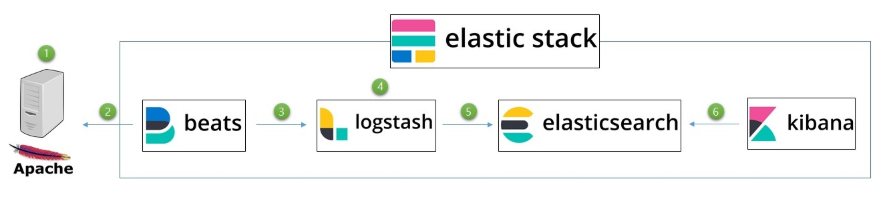
- 아파치 혹은 Nginx의 access.log에 외부 접근이 생기면 정해진 로그 포맷에 따라 파일이 생성되거나 내용이 추가됩니다.
- filbeat는 마치 리눅스의 tail명령어와 같이 지속적으로 파일을 읽어서 로그스태시에게 전달해줍니다. filebeat.yml 파일의 설정 파일로 target 로그스태시 지정이 가능합니다.
- logstash에서 input 모듈을 활용하면 beat에서의 내용을 받을 수 있습니다. 반드시 앞에 filebeat가 있어야 되는것이 아니고 로컬의 파일을 읽을 수도 있고, 혹은 외부 json 호출도 가능합니다.
- logstash의 강력한 기능중 하나인 filter를 통하여 log파일의 정제 및 reform이 가능합니다.
- 정제된 내용을 elastic으로 output으로 보내 줍니다.
- 키바나에서는 elastic의 내용을 표현해줍니다.
2. Docker-elk를 활용한 설치
지금까지 Docker에 대해서 학습을 해왔기 때문에 Docker로 설치해보고자합니다. 개별제품군으로 설치를 하면 귀찮지만, Docker를 한번에 ELK 스택을 한번에 올릴 수 있어 굉장히 편합니다.
2-1. docker-elk repository clone
작업 디렉토리에서 docker-elk git 레포지토리를 clone 합니다.
$ git clone https://github.com/deviantony/docker-elk#requirements
2-2. configuration
docker-elk를 clone 받으면 docker-elk 폴더가 생기고 여기서 각 config 폴더 안에 elk에 대한 설정을 해주면됩니다.
- elasticsearch.yml
- logstash.yml / logstash.conf
- kibana.yml
2-3. docker-elk 실행
# docker-compose.yml이 있는 디렉토리에서 수행해야 한다
# build
$ docker-compose build
# 빌드를 통해 생성된 도커 이미지 확인
$ docker images
# up: 컨테이너 생성 및 구동, -d는 백그라운드로 실행 옵션
$ docker-compose up -d
# 컨테이너 목록 확인
$ docker-compose ps
# 컨테이너 로그 확인
$ docker-compose logs -f
컨테이너 목록 확인에 정상적으로 컨테이너 3개(elasticsearch, logstash, kibana)가 보이고, 로그에서도 문제가 없으면 정상적으로 작동된 것이다. 브라우저에서 localhost:5601로 접속하면 kibana 웹 UI 화면이 뜰 것이다.
2-4. filebeat 설치
elk에 대한 내용은 설치를 완료했고, 필자 같은 경우, filebeat는 직접 host에 설치를 했습니다.
- filebeat 설치
filebeat 를 yum을 통해서 설치
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch/etc/yum.repods.d/elastic.repo 추가
[elastic-6.x] name=Elastic repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
yum install filebeat를 통해서 설치를 진행합니다.
3. 설정
이제 각 설정을 통해서 연결을 해줍니다.
3-1. filebeat 설정
filebeat 에서는 json 형태로 logstash 에게 데이터를 전달하고, 이때 message 필드에 수집한 로그 파일의 데이터가 담겨진다. 수집하려는 log file 의 유형에 따라서 community beats를 사용할 수도 있지만, 필자의 경우에는 Custom pattern의 로그 파일을 수집할 예정이라 logstash에서 pasring 하는 형태를 선택했다.
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- type: log
enabled: true
paths:
- /var/log/my_log_path/*.log
fields:
index_name: "my_custom_file_index_name"
#----------Elasticsearch output--------------- 주석처리
# (beats 에서 바로 ES 로 데이터 전달하지 않음)
#----------Logstash output ------------------- 주석해제
# (beats 에서 logstash 로 데이터 전달)
output.logstash:
# The Logstash hosts
hosts: ["my-logstash-server-host:5044"]
...
filebeat는 굉장히 심플하다. 1)target으로 보내주는 파일지정과 2) target에 대한 셋팅만 하면된다. 필자가 처음에 애먹었던 부분은 위에 보이는 것과 같이 elastic으로 바로 전달하면 안되기에 주석처리를 하고 logstash를 열어줘야되는데, logstash에 host만 셋팅하고 안되는 이유를 한참이나 찾았다.
3-2. logstash 설정
- grok, mutate, json, geoip, alter 필터를 설정했고 filebeat 에서 fields 로 넘겨받은 index_name을 사용했다.
- date 필터는 기준 시각을 filebeat 에 의해서 파싱된 시각을 사용하지 않고, log 에 기록된 시각으로 지정하도록 한다.

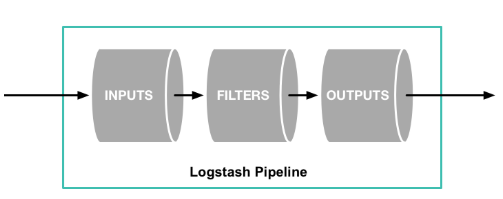
로그스태시의 기본구저는 INPUT, FILTERS, OUTPUT으로 이루어져있습니다.
input {
...
}
filter {
...
}
output {
...
}
아래는 필자가 만든 pipeline입니다. 파이프라인 설정을 통해서 비트로부터 넘어온 로그를 정정제하고 elasticsearch로 보내줍니다.
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "\"(?:%{WORD:verb} %{GREEDYDATA:uri_stem}\?%{GREEDYDATA:uri_query}(?: HTTP/%{NUMBER:httpversion})?|-)\" %{QS:agent}" }
}
if "_grokparsefailure" in [tags] {
drop { }
}
mutate {
gsub => [ "uri_query", "=(?<=\=)(.*?)(?=&|HTTP)", "",
"uri_query", "HTTP/1.0", "",
"uri_query", "HTTP/1.1", "",
"uri_query", "nocache", "",
"uri_query", "kkkkk", ""
]
split => { "uri_query" => "&" }
}
mutate {
remove_field => "message"
remove_field => "verb"
remove_field => "httpversion"
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["172.26.0.1:9200"]
index => "wonizz_nginx"
user => "elastic"
password => "changeme"
}
stdout { codec => rubydebug }
}
하나씩 의미를 확인해보겠습니다.
- input
beats {
port => 5044
}
내용에서 보다시피, filebeat로부터 오는 input에 대한 내용입니다. 기본적으로 5044 tcp 포트로 들어오는 데이터를 수집합니다.
- filter
grok {
match => { "message" => "\"(?:%{WORD:verb} %{GREEDYDATA:uri_stem}\?%{GREEDYDATA:uri_query}(?: HTTP/%{NUMBER:httpversion})?|-)\" %{QS:agent}" }
}
grok은 넘어오는 input에 대하여 동적으로 mapping하여 각 포맷별로 mapping시켜주는 것입니다. 예를들어 아파치나 nginx의 access.log는 정해진 포맷이 있는데 적절하게 grok 패턴을 사용하면 알아서 매핑을 해주어 쪼개줍니다.
아래의 2가지 웹사이트를 활용하여 필자는 custom되어있는 nginx로그를 매핑할 수 있는 grok 패턴을 만들어 봤습니다.
if "_grokparsefailure" in [tags] {
drop { }
}
단순히, grok mapping에 실패하였을 경우, continue 하는 내용입니다.
mutate {
gsub => [ "uri_query", "=(?<=\=)(.*?)(?=&|HTTP)", "",
"uri_query", "HTTP/1.0", "",
"uri_query", "HTTP/1.1", "",
"uri_query", "nocache", "",
"uri_query", "kkkkk", ""
]
split => { "uri_query" => "&" }
}
mutate는 그 의미에서도 알 수 있듯이 변형을 가하는 것입니다.
gsub는 substring을 하는 것이고, split은 쪼개는 것입니다.
위에서 보는 내용은 uri_query로 매핑되어 도출된 내용을 적절하게 substring하여 앰퍼센트(&)로 쪼개는 내용입니다.
예를들어, uri_query string이 “test=1&test2=2 HTTP/1.1″ 이라고 들어오면 첫줄의 정규식에 의하여 test&test2 HTTP/1.1” 이 남고 그다음부터는 substring으로 제거해줍니다.
test&test2는 split에 의하여 test, test2로 쪼개어 수집하게 됩니다.
mutate {
remove_field => "message"
remove_field => "verb"
remove_field => "httpversion"
}
불필요한 field에 대해서 삭제 처리합니다.
- output
elasticsearch {
hosts => ["172.26.0.1:9200"]
index => "wonizz_nginx"
user => "elastic"
password => "changeme"
}
elasticsearch 로 적절한 index로 넣게 됩니다. 여기서 host 같은 경우는 docker로 올렸기 때문에 해당 호스트이 docker daemon 의 network 를 호출하여 9200포트로 보내줍니다.
4. elasticsearch 조회
필자 같은경우는 elasticsearch에 넣고 kibana로 조회를 했지만, 알람을 주기 위해 zabbix를 활용했다.
먼저 nodejs를 활용하여 elastic에서 데이터를 조회합니다.
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200',
log: 'trace'
});
client.search({
index: 'wonizz_nginx',
type: '_doc',
body: {
"query": {
"bool": {
"must": [
{
"range": {
"@timestamp": {
"gte": "now-1h/h",
"lte": "now"
}
}
}
]
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "uri_query.keyword"
}
}
}
}
})
간단하게 elasticsearch 모듈을 import하여 조회를 손쉽게 할 수 있다.
필자가 하고자 했던것은 1시간 이전의 데이터를 수집한 뒤, aggregation을 이용하여 uri_query에 대해서 group by를 하고자 하는 것입니다.
앞서 이야기했듯이 whitelist되지 않은 parameter가 노출이 되면, 해당 내용을 .log파일로 출력하고, zabbix는 지속적으로 .log파일을 감시하다가 신규 내용이 올라오면, 알람을 주는 구조입니다.
elasticsearch <-> nodejs -> requset_parameter.log 파일 <- zabbix 감시
5. 마치며…
이번시간에는 ELK와 Filebeat를 통해서 로그 수집에 대해서 알아봤습니다. 아직은 기초적인 단계이지만, 잘만 활용하면 전체적인 로그의 모습을 볼 수 있고 또한 access.log같은 경우 패턴도 분석이 가능할 것 같습니다.
ELK 스택에서 제공해주는 로그 패턴 분석으로 알람까지 주는 기능도 좀더 알아봐야될 것 같습니다.
다음이시간에는 Elasticsearch 클러스터 구성에 대해서 알아보는 시간을 갖도록 하겠습니다.